- Veröffentlicht am
Kimi k1.5: Multimodales Modell auf OpenAI-o1-Ebene
- Autoren

- Name
- Trường Hoàng
- @truong11t2
Inhaltsverzeichnis

Generative KI gewinnt immer mehr an Bedeutung. Aber wie wir alle vermutet haben, sind es nicht OpenAI oder Google oder Meta, sondern chinesische Firmen, die mit von der Partie sind, zuerst mit DeepSeeks Blockbuster-Veröffentlichungen wie DeepSeek – v3 und DeepSeek-R1 und jetzt mit Kimi k1.5 von MoonShot AI, das bei einigen wichtigen Benchmarks große Namen wie GPT-4o und Claude3.5 Sonnet übertroffen hat.
Was ist Kimi k1.5?
Kimi 1.5 ist ein multimodales LLM, das mit Reinforcement Learning (RL) trainiert und von MoonShot AI entwickelt wurde, um bei verschiedenen Denkaufgaben in den Bereichen Text, Vision und Codierung hervorragende Ergebnisse zu erzielen.
Hauptfunktionen von Kimi 1.5
Reinforcement Learning (RL)-Training:
Kimi 1.5 nutzt RL, um seine Denkfähigkeiten zu verbessern, sodass es Belohnungen erkunden und daraus lernen kann, anstatt sich ausschließlich auf statische Datensätze zu verlassen. Das RL-Framework ist so konzipiert, dass es simpel, aber dennoch effektiv ist und komplexe Techniken wie Monte-Carlo-Baumsuche oder Wertfunktionen vermeidet.
Skalierung langer Kontexte:
Kimi 1.5 skaliert sein Kontextfenster auf 128.000 Token, sodass es längere Denkketten und komplexere Probleme verarbeiten kann. Das Modell verwendet partielle Rollouts, um die Trainingseffizienz zu verbessern, und verwendet Teile vorheriger Trajektorien wieder, um die Neugenerierung neuer Trajektorien von Grund auf zu vermeiden. Verbesserte Richtlinienoptimierung: Das Modell verwendet eine Variante des Online-Mirror-Descents für eine robuste Richtlinienoptimierung, kombiniert mit effektiven Sampling-Strategien und Längenstrafen zur Leistungssteigerung. Die Richtlinienoptimierung soll die Erkundung verschiedener Denkpfade fördern und die Fähigkeit des Modells verbessern, komplexe Probleme zu lösen.
Was ist Online-Mirror-Descent?
Stellen Sie sich vor, Sie versuchen, den besten Schulweg zu finden, um dem Verkehr aus dem Weg zu gehen. Sie haben einige Optionen: Weg A, Weg B und Weg C. Jeden Tag wählen Sie einen Weg und sehen, wie lange Sie zur Schule brauchen.
So funktioniert Online Mirror Descent:
Wählen Sie einen Weg: Sie beginnen, indem Sie einen der Wege wählen (sagen wir Weg A).
Beobachten Sie das Ergebnis: Nachdem Sie Weg A gewählt haben, sehen Sie, wie lange Sie zur Schule brauchen. Vielleicht dauert es 15 Minuten.
Passen Sie Ihre Strategie an: Am nächsten Tag verwenden Sie die Informationen vom Vortag, um eine bessere Wahl zu treffen. Wenn Weg A gut war, wählen Sie ihn vielleicht wieder, wenn er aber schlecht war (sagen wir, er hat 30 Minuten gedauert), probieren Sie vielleicht Weg B oder Weg C.
Wiederholen: Sie machen das jeden Tag und passen Ihre Wahl basierend auf den Erfahrungen des Vortages an.
Online Mirror Descent ist, als würden Sie verschiedene Schulwege ausprobieren und Ihre Wahl basierend auf der Dauer jedes Weges anpassen. Es hilft Ihnen, den besten Weg zu finden, indem es aus Ihren vergangenen Erfahrungen lernt.
Multimodale Fähigkeiten:
Kimi 1.5 wird gemeinsam mit Text- und Bilddaten trainiert, sodass es effektiv über beide Modalitäten hinweg argumentieren kann. Das Modell kann Aufgaben bewältigen, die sowohl Text- als auch Bildverständnis erfordern, wie z. B. das Interpretieren von Diagrammen, Schaubildern und anderen visuellen Inhalten.
Long2Short-Methoden:
Kimi 1.5 führt Techniken ein, um die Argumentationsfähigkeiten von Long-Chain-of-Thought-Modellen (CoT) auf Short-CoT-Modelle zu übertragen und so deren Leistung mit begrenzten Token-Budgets zu verbessern. Man kann es als ähnlich der „Wissensdestillation“ in ML betrachten. Methoden wie Modellzusammenführung, Shortest Rejection Sampling und Long2Short RL werden verwendet, um die Token-Effizienz zu verbessern. Was die Leistung betrifft, hat das Team Benchmarks für Long CoT und Short CoT veröffentlicht:
Long Chain-of-Thought (CoT) beinhaltet einen detaillierten, schrittweisen Argumentationsprozess zur Lösung komplexer Probleme, der oft mehr Rechenressourcen erfordert. Short CoT hingegen zielt darauf ab, ähnliche Ergebnisse mit weniger Schritten zu erzielen, was es schneller und effizienter, aber möglicherweise weniger gründlich macht.
Leistung und Metriken (Long CoT)
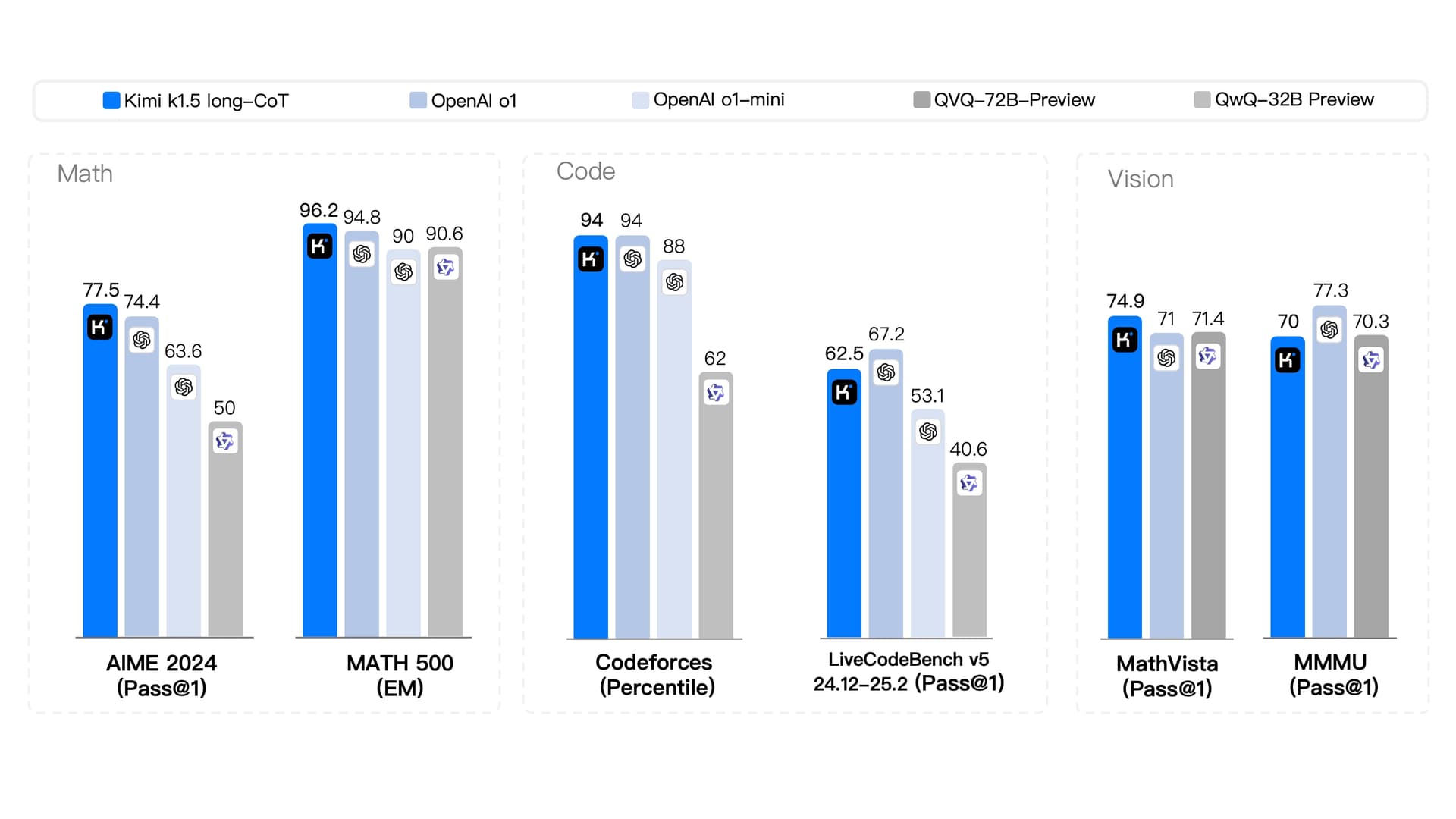
Mathematik
AIME 2024: Kimi erreicht 77,5 %, deutlich mehr als OpenAI o1 (74,4 %) und andere (nur 50 % für QwQ-32B).
MATH 500: Kimi dominiert mit 96,2 % und übertrifft OpenAI o1 (94,8 %) und andere (bis zu 90 %) leicht.
Code
Codeforces: Kimi erreicht 94 %, gleichauf mit OpenAI o1, aber weit vor QwQ-32B (62 %).
LiveCodeBench v5: Kimi erreicht 62,5 %, knapp hinter OpenAI o1 (67,2 %), aber deutlich besser als QwQ-32B (40,6 %).
Vision
MathVista: Kimi führt mit 74,9 % und schlägt OpenAI o1 (71 %) und andere.
MMMU: Kimi hinkt in diesem Benchmark gegenüber o1 hinterher.
Leistung und Metriken (Short CoT)
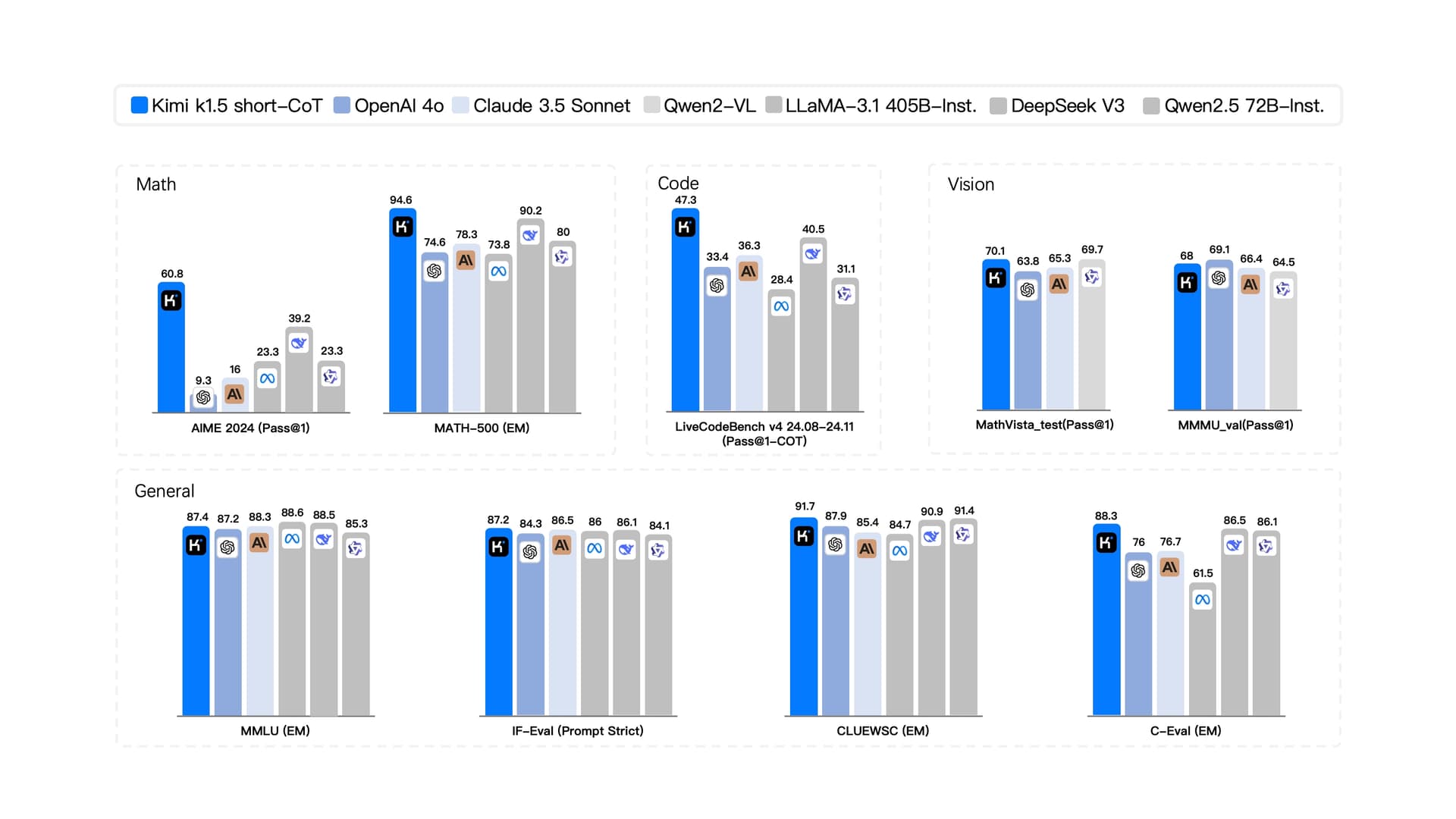
Mathematik:
AIME 2024 (Pass@1): Kimi k1.5 erreicht 60,8 Punkte, was deutlich höher ist als die 9,3 von OpenAI O1 und eine starke Leistung bei der unmittelbaren Problemlösung in Mathematik zeigt.
Math-500 (EM): Es erreicht 94,8 Punkte, was deutlich besser ist als die 74,6 von OpenAI O1, was darauf hindeutet, dass Kimi k1.5 die Nase vorn hat.
Code:
LiveCodeBench v4 24.08–24.11 (Pass@1-CoT): Kimi k1.5 erreicht 47,3 Punkte, was höher ist als OpenAI O1s 33,4, und zeigt eine bessere Leistung bei Code-bezogenen Aufgaben, die sofortige Ausführung und Korrektheit erfordern.
Vision:
MathVista_test(Pass@1): Kimi k1.5 erreicht 70,1 Punkte, was höher ist als OpenAI O1s 63,8, was auf eine bessere Leistung bei Vision-Aufgaben hinweist, die mathematisches Denken erfordern.
MMVLU_val(Pass@1): Es erreicht 68 Punkte, was etwas niedriger ist als OpenAI O1s 69,1, was zeigt, dass beide Modelle bei dieser Vision-Aufgabe eng beieinander liegen.
Allgemein:
MMLU (EM): Kimi k1.5 erreicht 87,4 Punkte, was etwas höher ist als OpenAI O1s 87,2, was auf eine marginale Verbesserung bei allgemeinen Wissensaufgaben hinweist.
IF-Eval (Prompt Strict): Es erreicht 87,2 Punkte, was höher ist als die 84,3 von OpenAI O1, und zeigt eine bessere Leistung bei Aufgaben, die eine strikte Einhaltung von Eingabeaufforderungen erfordern.
CLUEWSC (EM): Kimi k1.5 erreicht 91,7 Punkte, was höher ist als die 87,9 von OpenAI O1, was auf eine bessere Leistung bei Aufgaben zum Verständnis der chinesischen Sprache hinweist.
C-Eval (EM): Es erreicht 88,3 Punkte, was höher ist als die 76 von OpenAI O1, und zeigt eine deutliche Verbesserung bei umfassenden Bewertungsaufgaben.
Insgesamt scheint Kimi k1.5 also ein Monster von einem Modell zu sein und könnte auch DeepSeek-Modellen Konkurrenz machen.
Wie kann man Kimis k1.5 kostenlos nutzen?
Obwohl das Modell nicht Open-Source ist, kann es auf der Plattform ausprobiert werden
Sie können sich auch für eine kostenlose API bewerben: https://forms.gle/TqZ9XQnPiJPddzhV8